
크루스칼 알고리즘
- 그리디를 사용하여 그래프의 최소 신장 트리를 구하는 알고리즘
- 최소 신장 트리가 1) 최소 가중치의 간선으로 구성, 2) 사이클을 포함하지 않다는 조건으로 각 단계에서 사이클을 이루지 않는 최소 가중치 간선을 선택한다.
동작
- 그래프의 간선들을 가중치의 오름차순으로 정렬한다.
- 정렬된 간선 리스트에서 순서대로 사이클을 형성하지 않는 간선을 선택한다.
- 가장 낮은 가중치를 먼저 선택
- 사이클을 형성하는 간선을 제외
- 해당 간선을 현재의 최소 신장 트리의 집합에 추가한다.
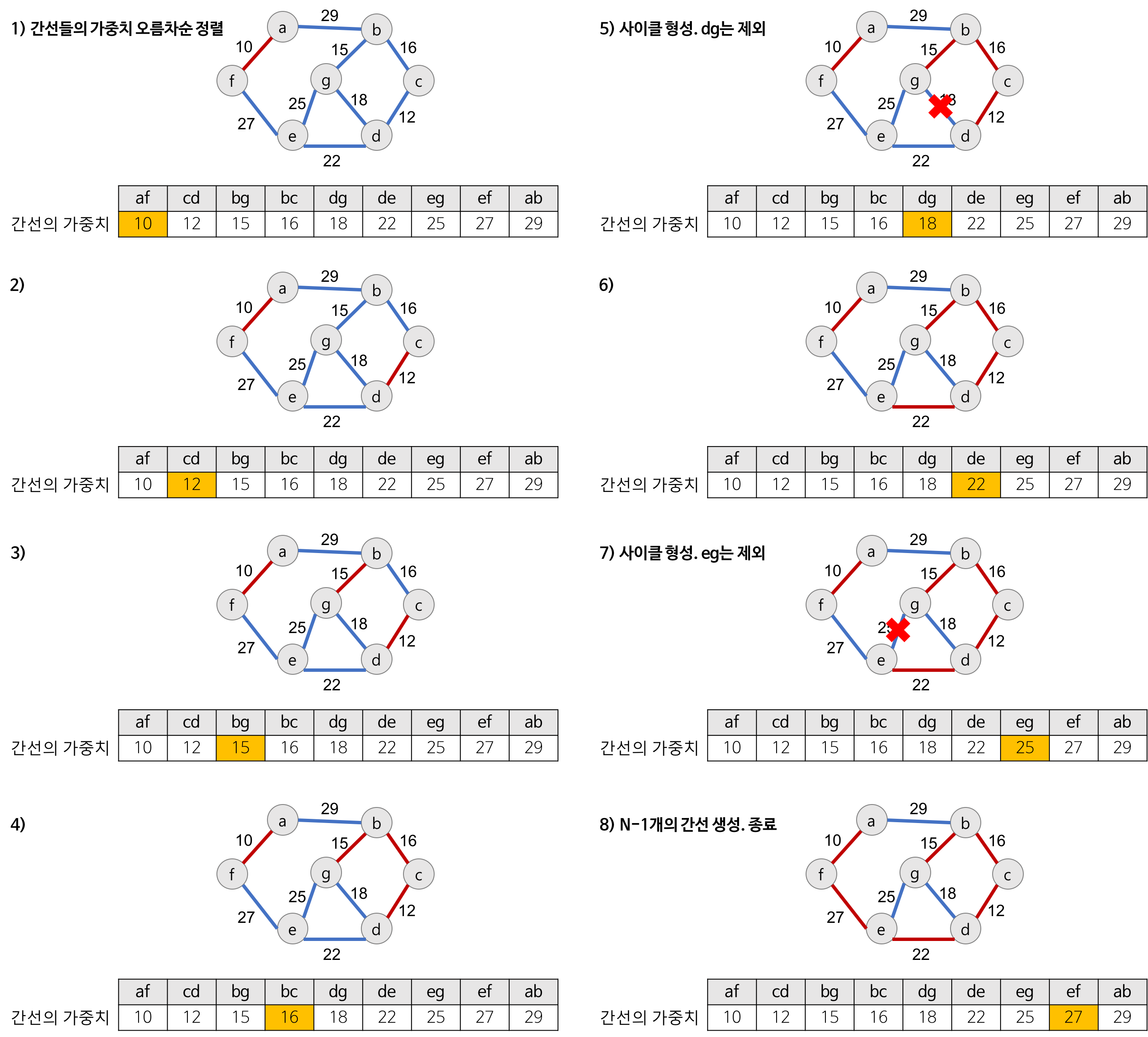
- 주의할 점은 간선을 선택할 때, 해당 간선이 사이클을 생성하는지 그 여부를 확인해야 하는데, 그 여부를 검사하기 위해 유니온 파인드 알고리즘을 이용해야 한다.
Disjoint-Set
- 유니온 파인드 알고리즘에 대해 공부하기 전 Disjoint-Set의 개념에 대해 알아야 한다.
- disjoint-set은 중복되지 않은 부분 집합들로 나눠진 원소들에 대한 정보를 저장하고 조작하는 자료구조이다.
- 즉, 공통 원소가 없는 상호-배타적인 부분 집합들로 나눠진 원소들에 대한 자료구조이다.
- Disjoint-Set = 서로소 집합 자료구조
유니온 파인드 알고리즘
- Disjoint-Set을 표현할 때 사용하는 알고리즘
- 집합을 구현하는 데 비트 벡터, 배열, 연결 리스트를 이용할 수 있으나 그 중 가장 효율적인 트리 구조
- 아래 세 가지 연산을 이용해서 Disjoint-Set을 표현한다.
- make-set(x)
- 초기화
- x를 유일한 원소로 하는 새로운 집합
- union(x, y)
- 합하기
- x가 속한 집합과 y가 속한 집합을 합친다. 즉, x와 y가 속한 집합을 합치는 연산
- find(x)
- 찾기
- x가 속한 집합의 대표값(루트 노드 값)을 반환한다. 즉, x가 어떤 집합에 속해 있는지 찾는 연산
- make-set(x)
- 유니온 파인드 알고리즘을 트리 구조로 구현하는 이유?
- 배열의 경우
- Array[i]: i번 원소가 속하는 집합의 번호(=루트 노드의 번호)
- make-set(x)
- Array[i] = i와 같이 각자의 집합 번호로 초기화한다.
- union(x, y)
- 배열의 모든 원소를 순회하면서, y의 집합 번호를 x의 집합 번호로 변경한다.
- 시간 복잡도 O(N)
- find(x)
- 한 번만에 x가 속한 집합 번호를 찾는다. (배열 값)
- 시간 복잡도 O(1)
- 트리의 경우
- 같은 집합 = 하나의 트리, 즉 집합 번호 = 루트 노드
- make-set(x)
- 각 노드는 모두 루트 노드이므로, N개의 루트 노드 생성 및 자기 자신으로 초기화 한다.
- union(x, y)
- x, y의 루트 노드를 찾고 다르면 y를 x의 자손으로 넣어 두 트리를 병합한다.
- 시간 복잡도 O(N)보다는 작은게 자명하므로, find 연산이 전체 수행을 지배
- find(x)
- 노드의 집합 번호는 루트 노드, 루트 노드를 확인해서 같은 집합인지 확인
- 시간 복잡도: 트리의 높이와 시간 복잡도가 동일(최악 O(N-1))
- 즉 트리 구조로 표현하면 배열보다 시간 복잡도를 더 줄일 수 있다
- 배열의 경우
과정
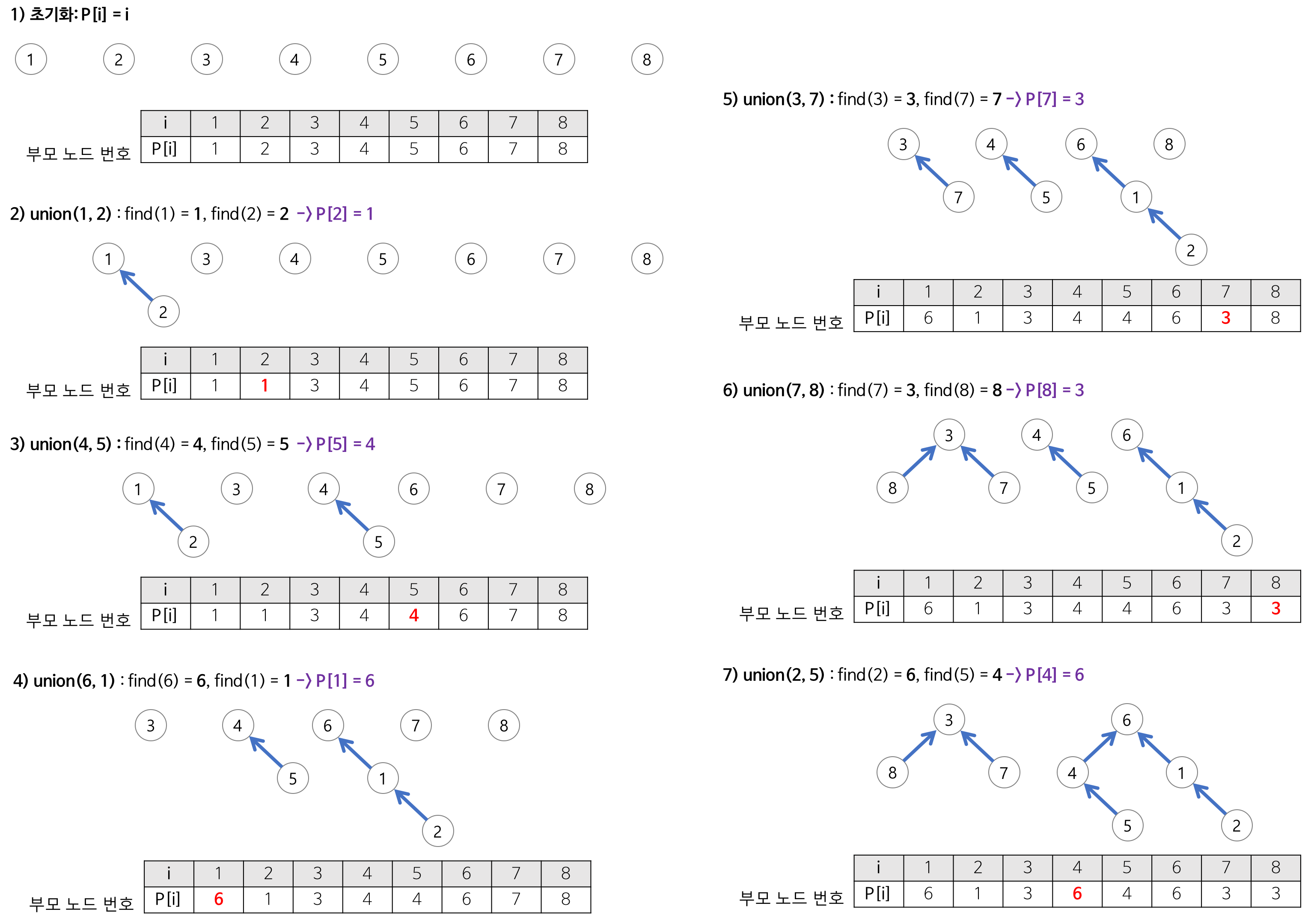
- 임의의 집합을 분할한다는 것은 각 부분 집합이 아래 두 가지 조건을 만족하는 Disjoint Set이 되도록 쪼개는 것이다.
- 분할된 부분 집합을 합치면 원래의 전체 집합이 된다.
- 분할된 부분 집합끼리는 겹치는 원소가 없다
유니온 파인드의 최적화

- 위와 같이 연결 리스트 형태 일 때 트리의 높이가 최대가 된다. 즉, 편증 현상이 발생된다.
- 원소의 개수가 N일 때, 트리의 높이가 N-1 이므로 union과 find(x)의 시간 복잡도가 모두 O(N)이 된다.
- 결국 배열로 구현하는 것 보다 비효율적이다.
find 연산 최적화
- 경로 압축(path compression) 이라고 한다
- 시간 복잡도: O(logN)
- 방법은 find 하면서 만난 모든 값의 부모 노드를 root로 만드는 것이다.
union 연산 최적화
- union-by-rank라고 한다
- rank배열에 트리의 높이를 저장하고, 항상 높이가 더 낮은 트리를 높은 트리의 밑에 넣어서 합치는 방법이다.
크루스칼 알고리즘의 시간복잡도
- O(ElogE)
- 시간이 가장 오래걸리는 부분은 간선을 정렬하는 작업이고
- E개의 데이터를 정렬하였을 때, 시간 복잡도는 O(ElogE)이기 때문
- 그외의 disjoint-set 알고리즘의 시간 복잡도가 정렬 알고리즘의 시간 복잡도 보다 작으므로 무시할 수 있다.
Uploaded by N2T

